In today’s dynamic digital landscape, data is frequently dubbed as the new oil. However, as with crude oil, the true value of data lies not in its raw state but in its refinement: processing, analyzing, and leveraging it to inform decisions. DevOps and Data Engineering often intertwine, especially as DevOps principles are increasingly applied in the data domain, giving rise to the term “DataOps.” As data volumes have surged and the pace of business has intensified, the methodologies used to manage and harness data have consequently evolved. Enter DataOps.
Definition: At its core, DataOps can be understood as the application of DevOps principles to data workflows. If DevOps is about enhancing software development through continuous delivery, integration, and collaboration, DataOps takes a leaf out of that book but specifically targets the unique challenges and intricacies of the data domain. The focus here is not just on the data itself but on the processes, systems, and teams that handle it, ensuring a streamlined flow of data through its lifecycle.
Evolution: The concept of DataOps didn’t emerge in isolation. It was born out of a confluence of needs. With businesses increasingly relying on data-driven insights and with data sources becoming more varied and voluminous, traditional data management practices began to show their limitations. Speed, scalability, and collaboration became paramount. DataOps, as an approach, traces its roots back to these industry demands and the successful paradigms established by DevOps. Over time, as the industry started recognizing the gaps between data teams (from engineers to scientists to analysts) and the operational challenges they faced, DataOps began to solidify as a distinct discipline in data management.
The continuous evolution in technology and business demands has brought about various methodologies and practices. While DevOps primarily emerged as a bridge between software development and IT operations, ensuring swift and efficient software releases, its foundational principles found resonance in another crucial domain: data engineering. This synergy paved the way for DataOps. To grasp the essence of DataOps, one must first understand its parallels with DevOps.
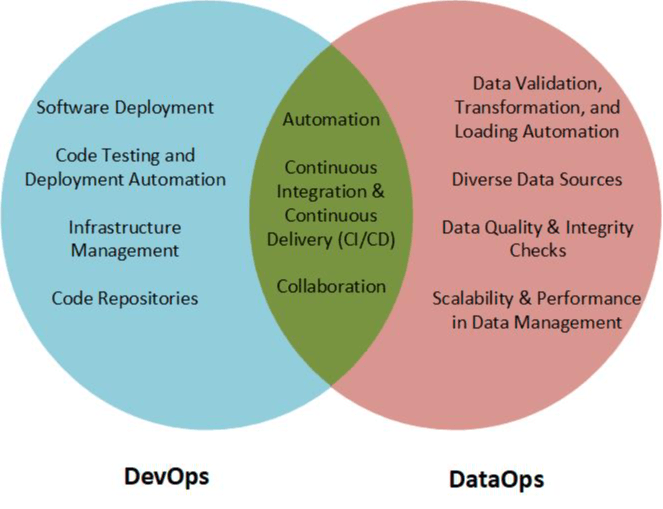
Venn diagram showing the overlapping principles of DevOps and DataOps
Automation: Just as DevOps emphasizes the automation of software deployment and infrastructure changes to ensure consistent and rapid delivery, DataOps recognizes the need for automating data pipelines. This automation reduces manual intervention, minimizes errors, and accelerates data processing. For instance, where DevOps might automate code testing and deployment, DataOps automates data validation, transformation, and loading processes. Imagine a global e-commerce platform. Where DevOps might ensure that the platform itself remains bug-free and user-friendly through automated testing, DataOps ensures that when a customer views a product, the stock count, price, and other product details are up-to-date and accurate, achieved through automated data validation and loading.
Continuous Integration and Continuous Delivery (CI/CD): The heart of DevOps lies in the CI/CD pipeline, which ensures that code changes are continuously integrated, tested, and delivered to production. Similarly, DataOps adopts CI/CD but in the realm of data. It ensures that data from various sources integrates seamlessly, is consistently refined, and is delivered to data warehouses or analytics tools without hiccups. This continuous flow ensures that businesses always have access to timely and reliable insights.
Collaboration: DevOps introduced a culture where developers and IT operations teams collaborated closely, breaking down silos. DataOps extends this collaborative approach to include data engineers, data scientists, and business stakeholders. The objective is the same: fostering an environment where cross-functional collaboration results in optimal outcomes, whether it’s software products in DevOps or data-driven insights in DataOps. For instance, a tech company launching a new device might need both software updates (managed by DevOps) and real-time market data for pricing and promotion (handled by DataOps). Seamless collaboration between these teams can ensure a successful launch.
While the foundational principles might be shared, it’s essential to understand that data has its own set of complexities. This is where DataOps customizes these principles.
Diverse Data Sources: Unlike code repositories, which are relatively standardized, data can come from a plethora of sources: IoT devices, user interactions, databases, third-party APIs, and more. DataOps ensures that the principle of continuous integration is agile enough to handle this diversity, integrating data from varied sources into a cohesive dataset.
Data Quality and Integrity: Data isn’t always clean or reliable. Unlike software bugs that are generally consistent in nature, data anomalies can be random and multifaceted. DataOps, drawing from the automation principle, incorporates automated data quality checks and validation processes, ensuring that the data utilized is accurate and trustworthy.
Scalability and Performance: Data volumes are ever-growing. While DevOps deals with the scalability of applications and infrastructure, DataOps must ensure that data infrastructures and pipelines scale efficiently, processing ever-larger datasets without performance bottlenecks.
In essence, DataOps is not just a mere adoption of DevOps principles but a meticulous adaptation, ensuring these principles serve the unique demands and challenges of the data world. It’s this careful melding of principles and customizations that makes DataOps a vital methodology in today’s data-driven enterprises.
In the evolving landscape of data-driven decision-making, organizations are under constant pressure to efficiently utilize their data resources. With the sheer volume and diversity of data at play, traditional data management techniques often fall short of delivering timely insights.
DataOps, as a solution, steps into this arena, emphasizing not just the methods but the value it brings to the table. The importance of DataOps is manifold, addressing time-to-value, collaborative efficiency, and data quality with remarkable efficacy.
In the world of business, time is money. The quicker raw data is converted into actionable insights, the faster organizations can make informed decisions, be it launching a new product, refining marketing strategies, or identifying operational inefficiencies. DataOps plays a pivotal role here:
Streamlined Workflows: By applying continuous integration and delivery principles, DataOps ensures that data pipelines are smooth, reducing the lag between data acquisition and data consumption.
Automated Processes: Data validation, transformation, and loading are automated, minimizing manual interventions that often lead to delays.
Airlines use DataOps to quickly process vast amounts of flight data, weather conditions, and passenger preferences to optimize flight schedules, pricing, and in-flight services. This immediate processing can lead to improved customer experience and efficient operations.
The true potential of data is realized when diverse teams —including data engineers, data scientists, and business stakeholders—work in unison. DataOps fosters this synergy.
Unified Data Platforms: DataOps encourages the use of platforms where teams can collaboratively view, access, and work on data. This shared workspace reduces back-and-forths and promotes parallel processing.
Shared Objectives: With clear communication channels, teams are better aligned in their goals, ensuring that the data engineering process serves the larger business objectives.
High-quality insights require high-quality data. With the vastness and varied nature of data sources, ensuring data consistency and reliability is paramount. This is where DataOps shines:
Automated Quality Checks: Just as code undergoes tests in DevOps, DataOps incorporates automatic data quality assessments, ensuring anomalies are detected and rectified early in the pipeline. Consider financial institutions like JP Morgan, where trading algorithms are based on vast amounts of data. It’s not just about quantity; the quality of this data is paramount. A single discrepancy could lead to significant financial discrepancies. Through DataOps’ automated quality checks, the bank ensures that its algorithms operate on accurate, validated data, reducing potential risks.
Version Control: Borrowing from DevOps, DataOps often uses version control for data, ensuring that every stakeholder accesses the most recent, consistent version of the dataset.
Feedback Loops: Continuous monitoring of data pipelines means that any discrepancies in data quality are flagged and fed back into the system for improvements. This iterative approach enhances the reliability of the data over time.
In the midst of an information age where data is plentiful but actionable insights are gold, DataOps stands as a beacon, guiding organizations to effectively harness their data potential. By focusing on quick turnarounds, collaboration, and quality, DataOps ensures that data engineering is not just about managing data but truly empowering businesses.
A representation of each challenge: scalability, data variety, real-time processing, and data security
In today’s digital era, businesses are inundated with data. Yet, while data is undeniably a valuable asset, it comes with its own set of challenges. These challenges, if not addressed, can hinder an organization’s ability to make informed decisions, strategize effectively, and maintain a competitive edge. DataOps, as a forward-thinking methodology, aims to alleviate these pain points. Let’s delve into the core challenges DataOps addresses:
With data streaming in from a myriad of sources, data infrastructures often buckle under the strain of ever-expanding data volumes. Traditional systems might be ill-equipped to handle this influx, leading to performance degradation and bottlenecks.
Dynamic Scaling: DataOps encourages the use of cloud-based solutions and containerization, allowing data infrastructures to dynamically scale as per the data volume. This ensures smooth and efficient data processing irrespective of the data load. For instance, Netflix, known for its massive user base, leverages DataOps principles to handle petabytes of data daily, ensuring that their recommendation algorithms and content delivery networks run efficiently.
Resource Optimization: Through continuous monitoring and feedback loops, DataOps ensures that resources are optimally utilized, preventing over-provisioning and wastage.
Data heterogeneity poses another challenge. Organizations handle data that ranges from structured datasets in relational databases to unstructured data from social media, logs, and IoT devices.
Unified Data Platforms: DataOps promotes the creation of platforms where diverse datasets can be integrated, transformed, and standardized, thus offering a cohesive view of data. Coca-Cola, for example, integrates data from various sources such as sales figures, social media feedback, and supply chain data using DataOps techniques to gain a holistic view of its global operations.
Metadata Management: DataOps practices often emphasize robust metadata management, aiding in understanding, categorizing, and utilizing diverse datasets effectively.
In an age where real-time insights can be a game-changer, the demand for real-time data processing has surged. This requires handling data streams efficiently and processing them without delays.
Streamlined Pipelines: DataOps ensures that data pipelines are designed for low latency, handling data streams efficiently and delivering real-time insights. Companies like Uber utilize DataOps to process real-time data on traffic, driver availability, and user demand to efficiently match drivers with riders.
Event-Driven Architectures: DataOps often leans on event-driven architectures, which respond in real-time to data changes or specific events, ensuring timely data processing and analytics.
With data breaches becoming increasingly common and regulations like GDPR in place, data security and compliance cannot be overlooked.
End-to-End Encryption: DataOps emphasizes encrypting data at rest and in transit, ensuring that sensitive information is always secure.
Automated Compliance Checks: With tools integrated into the DataOps workflow, compliance checks are automated, ensuring data handling adheres to regulatory standards consistently.
Access Control: Role-based access controls are instituted, making sure that only authorized personnel can access and modify sensitive data.
In addressing these challenges, DataOps transforms the daunting task of data management into a streamlined, efficient, and secure process. Organizations armed with DataOps are better positioned to harness their data’s potential, ensuring that data-related challenges are not roadblocks but mere stepping stones toward a data-driven future.
Implementing DataOps can significantly refine an organization’s data engineering processes, but the effectiveness of this methodology hinges on the adoption of best practices. These practices act as guideposts, ensuring that DataOps not only integrates smoothly into the existing data ecosystem but also realizes its transformative potential. Here’s a comprehensive look at these best practices:
I was planning to place here illustration of a successful team working together but found this one and couldn’t hold back
Defining the North Star: Before diving into DataOps, organizations must outline their primary goals. Whether it’s streamlining data processing, bolstering data quality, or fostering inter-departmental collaboration, a well-articulated objective is pivotal. Companies like Airbnb have emphasized the importance of setting clear objectives when transitioning to DataOps, which allowed them to streamline their vast property and user data more efficiently.
Quantifying Success: Key Performance Indicators (KPIs) act as tangible metrics of success. By setting quantifiable targets, organizations can gauge the efficacy of their DataOps practices and iteratively refine their approach. Without a set target, many organizations find themselves adrift in the vast sea of data, leading to wasted resources and missed opportunities.
Cross-functional Collaboration: The essence of DataOps lies in interdisciplinary teamwork. Assembling a diverse group comprising data scientists, engineers, and operations experts ensures a holistic approach to data challenges. Tech giants like Google stress the importance of diverse teams, drawing on varied expertise to tackle complex data scenarios.
Continuous Training: The fluid nature of data mandates that the team remains updated with prevailing trends and methodologies. Regular workshops and training sessions help maintain a cutting-edge team. Moreover, fostering soft skills like adaptability, effective communication, and problem-solving enhances the team’s ability to navigate the challenges of DataOps efficiently.
Assessment and Evaluation: The market is inundated with tools designed for containerization, orchestration, version control, and monitoring. Organizations should carefully assess their requirements, conduct pilot tests, and choose tools that align with their objectives and infrastructure. The plethora of available tools can be overwhelming. Prioritizing tools like Apache Airflow for orchestration or Docker for containerization, after meticulous assessment, can be beneficial. It’s also prudent to be wary of tools that promise the moon but might not align with the organization’s specific needs or existing infrastructure.
Integration Capabilities: The chosen tools should seamlessly integrate with existing systems, ensuring that the transition to a DataOps approach is smooth and devoid of disruptions.
Fostering Collaboration: Collaboration is the bedrock of DataOps. Creating a milieu where open dialogue is the norm and where teams from diverse domains unite to solve data challenges is paramount. Organizations that sideline this collaborative ethos often find themselves grappling with inefficiencies, even if they possess advanced tools.
Feedback Loops: Just as continuous integration and delivery are integral to DataOps, so is continuous feedback. Regularly collecting feedback from team members and stakeholders and acting on it refines the DataOps process over time.
Lifelong Learning: In the fast-evolving world of data, learning never stops. Promoting a culture where team members are encouraged to learn, experiment, and innovate ensures that the organization remains at the forefront of data management best practices.
In summary, while DataOps holds the promise of revolutionizing data engineering, the key to unlocking this potential lies in adhering to these best practices. They act as the bedrock upon which successful DataOps implementation is built, ensuring that data processes are agile, efficient, and in perfect harmony with business objectives.
As we’ve journeyed through the intricacies of DataOps, one thing is clear: its transformative potential in the realm of data engineering is immense. This isn’t just another buzzword or fleeting trend. It represents a paradigm shift. By incorporating DevOps principles into data workflows, organizations can experience heightened efficiency. Gone are the days of siloed operations, where data engineers, data scientists, and business stakeholders worked in isolation. DataOps bridges these divides, fostering a collaborative ecosystem where data-driven decisions are expedited, aligned with business objectives, and rooted in high-quality, reliable data.
Looking ahead, the future of DataOps seems promising and exciting. As technology continues to advance, we can anticipate the emergence of even more sophisticated tools that further simplify data engineering tasks, promoting automation and ensuring even tighter integration of data processes. Moreover, as organizations globally recognize the merits of DataOps, we might witness the development of new methodologies, best practices, and standards that further refine this discipline.
Furthermore, the growing emphasis on artificial intelligence and machine learning will likely intertwine with DataOps. This union will give birth to intelligent data operations, where predictive analytics, automation, and adaptive data workflows become the norm.
A futuristic image symbolizing the future of DataOps
In conclusion, DataOps stands at the cusp of revolutionizing the world of data engineering. Its principles, methodologies, and practices hold the key to navigating the complexities of today’s data-driven world. As organizations continue to embrace and evolve with DataOps, the future of data engineering looks bright, collaborative, and extraordinarily efficient.
This article was originally published by Chingiz Nazar on Hackernoon.
The recent India–AI Impact Summit 2026 demonstrated a defining global inflection point — the transition…
The Tech Panda looks at Indian Fintech expanding to Sri Lankan Bank while a Swiss…
By enabling secure, consent-based financial data sharing, the Account Aggregator framework is laying the groundwork…
There’s a quiet crisis in one of medicine’s most exciting fields. Cell therapy – the…
Lenovo and NVIDIA are pushing AI into its next phase, scaling real-time, production-ready systems that…
AI is changing how work gets done. It’s also changing how people feel about their…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}