


Artificial Intelligence tools such as Bard, ChatGPT, and Bing Chat are the current big names in the Large Language Model (LLM) category which is on the rise.
LLMs are trained on vast data sets to be able to communicate by using everyday human language as a chat prompt. Given the flexibility and potential of LLMs, companies are integrating them into many workflows inside the tech industry to make our lives better and easier. One of the main AI-workflow integrations is an auto-complete code plugin, providing the ability to foresee and generate matching code patterns in order to code faster and more efficiently.
In the current market of AI code-generator tools, there are many players, including GitHub Copilot, Amazon CodeWhisperer, Google Cloud Code (Duet AI), Blackbox AI Code Generation, and more. This blog post outlines examples of common security pitfalls that developers face while using such tools.
The goal of this article is to raise awareness and emphasize that auto-generated code cannot be blindly trusted, and still requires a security review to avoid introducing software vulnerabilities.
Note: some vendors suggest that their auto-complete tools may contain insecure code snippets.
Many articles have already emphasized that auto-complete tools generate known vulnerabilities such as IDOR, SQL injection, and XSS. This post will highlight other vulnerability types that depend more on the code’s context, where there is a high probability for AI auto-complete to slip bugs into your code.
Security and AI Code Generating Tools AI models trained for code are usually trained on large code bases with the main mission of producing functioning code.
Many security issues have a known and defined way of mitigation without compromising the performance side (e.g. SQL injections could be avoided by not concatenating user input/parameters directly into the query) – and therefore, can be eradicated as there is no reason to write the code in an insecure manner.
However, many security issues are context-dependent which could be perfectly safe when implemented as internal functionality, while when facing external input from a client, become a vulnerability, and are therefore hard to distinguish through the AI’s learning dataset.
In such vulnerabilities, the specific usage of the code usually depends on other parts of the code and the application’s overall purpose.
Here are some common use cases and examples that we tested, showcasing some of these types of vulnerabilities:
- Use Case: Fetching Files from User Input – Arbitrary File Read
- Use Case: Comparing Secret Tokens – Type Juggling/Coercion
- Use Case: Forgot Password Mechanism – Unicode Case Mapping Collisions
- Use Case: Generating Configuration File – Bad Security Practices
- Use Case: Configuration Objects – Inconsistencies Leading to Insecure Deserialization
After seeing how the AI code generation tools handle the above cases, we tried to test their ability to create proper security filters and other mitigation mechanisms.
Here are some common use cases and examples that we tested by deliberately requesting secure code:
- Secure Code Request Use Case: Reading Files – Avoiding Directory Traversal
- Secure Code Request – File Upload – Restricted Extensions List
- Use Case: Fetching Files from User Input – Arbitrary File Read
Many applications include code that fetches a file back to the user based on a filename. Using directory traversal for reading arbitrary files on the server is a common method bad actors use to gain unauthorized information.
It may seem obvious to sanitize file name/file path input coming from the user before fetching the file back, but we assume it is a hard task for an AI model trained on generic codebases – this is because some of the datasets do not need to use sanitized pathsas part of their functionality (it may even downgrade performance or harm functionality) or are not harmed by unsanitized path as they are intended to be only for internal usage.
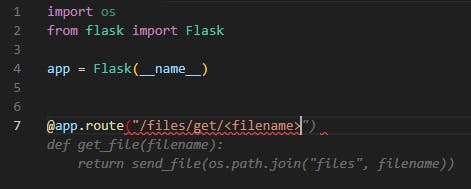
AI Tool Suggestion (Google Cloud Code – Duet AI): Let’s try to generate a basic file fetching function from user input, using Google Cloud Code – Duet AI auto-complete. We will let Duet AI auto-complete our code, based on our function & route names –
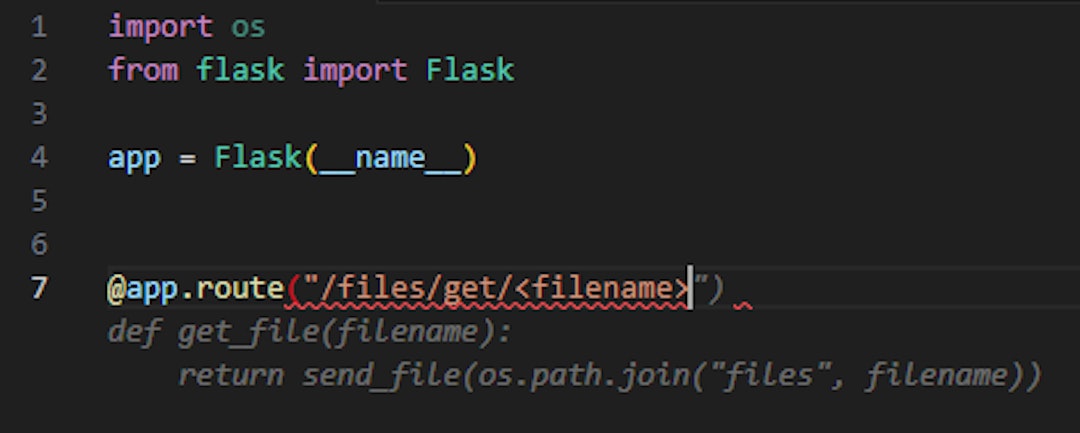
As we can see in gray, the autocomplete suggestion is to use Flask’s “send_file” function, which is Flask’s basic file-handling function.
But even Flask’s documentation states “Never pass file paths provided by a user”, meaning that while inserting user input directly to the “send_file” function the user will have the ability to read any file on the filesystem, for example by using directory traversal characters such as “../” in the filename.
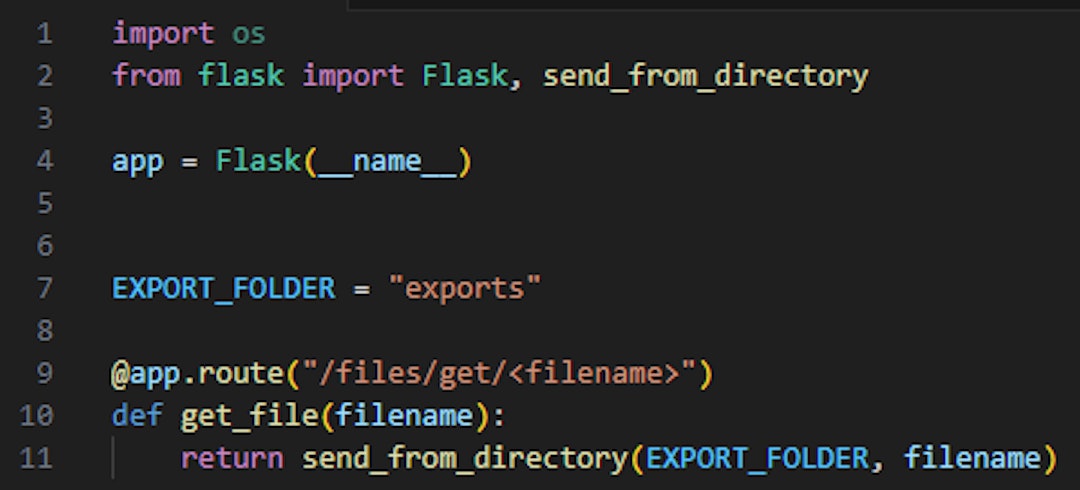
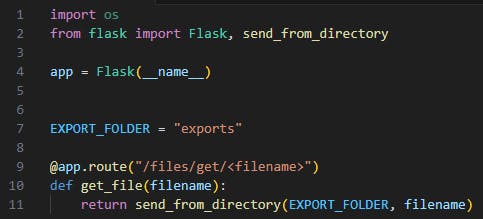
Replacing the “send_file” function with Flask’s safe “send_from_directory” function will mitigate the directory traversal risk. It will only allow fetching files from a specific hard-coded directory (“exports” in this case).
- Use Case: Comparing Secret Tokens – Type Juggling/Coercion
In some programming languages, such as PHP and NodeJS, it is possible to make comparisons between two different types of variables and the program will do a type conversion behind the scenes to complete the action.
Loose comparisons do not check the variable’s type behind the scenes and therefore are more prone to type juggling attack. However, the use of loose comparisons is not considered an insecure coding practice by itself – it depends on the context of the code. And again, it is difficult for AI models to tell the cases apart.
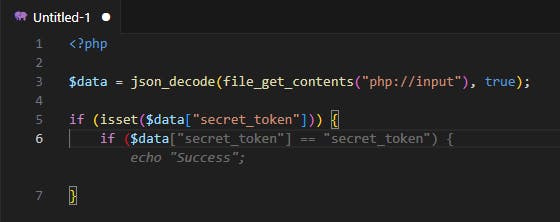
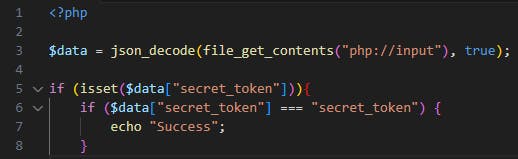
AI Tool Suggestion (Amazon CodeWhisperer): The most common example of PHP type juggling is loose comparisons of secret tokens/hashes where user input which is read via a JSON request (which enables control of the input’s type) reaches a loose comparison (“”) instead of a strict one (“=”).
As it appears, CodeWhisperer generates loose comparison conditions in auto-complete suggestions:
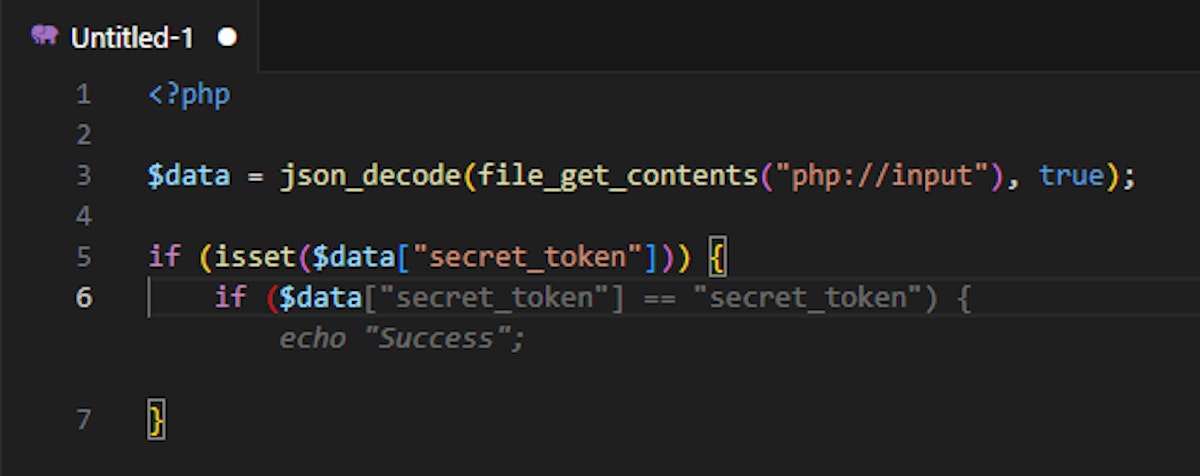
The loose comparison of the secret_token allows an adversary to bypass the comparison $data[“secret_token”] == “secret_token”. While submitting a JSON object with the value of “secret_token” being True (boolean), the loose comparison result is True as well (even on newer PHP versions).

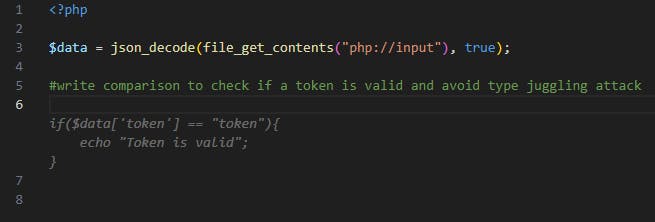
Even when “hinting” the tool (using a comment) to write the check “securely”, it did not generate a code snippet containing a strict comparison –
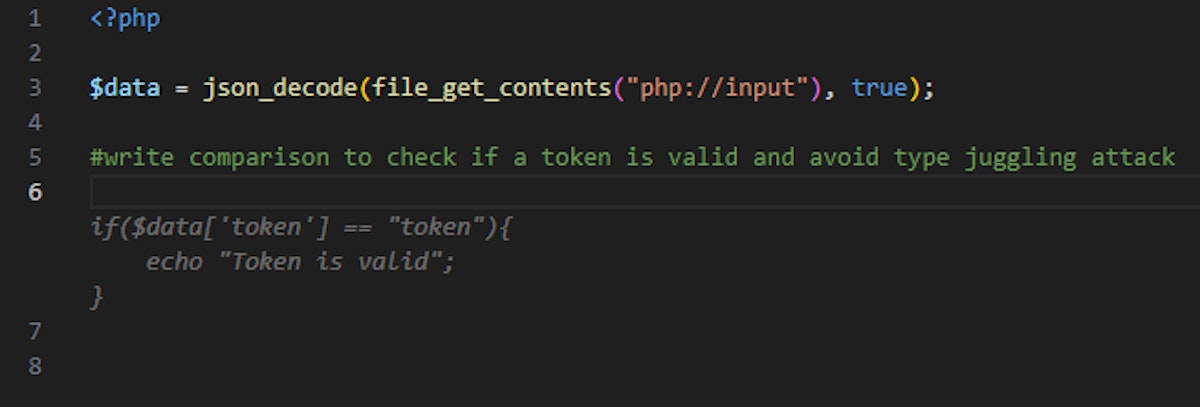
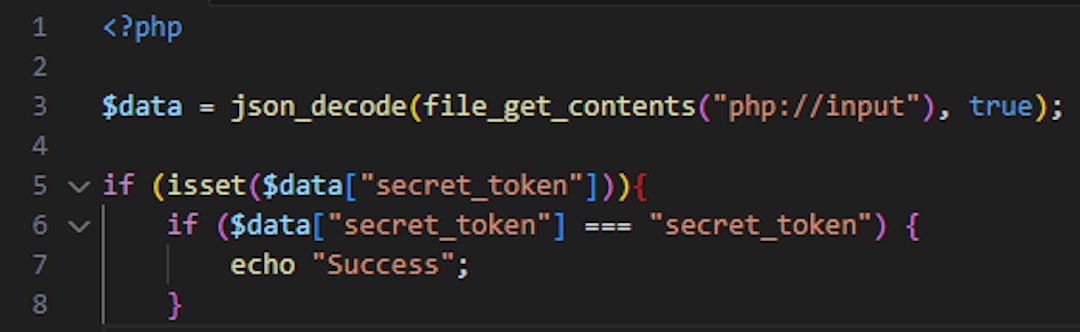
Only when specifying a strict comparison (“===”) we are protected against type juggling attacks.
- Use Case: Forgot Password Mechanism – Unicode Case Mapping Collisions
Vulnerabilities in the “Forgot Password” mechanism are very common in SaaS applications and were the root cause behind CVEs such as CVE-2017-8295(WordPress), CVE-2019-19844 (Django), and CVE-2023-7028 (GitLab).
Specifically, a Unicode Case Mapping Collision vulnerability occurs when user input is either uppercased or lowercased in a comparison expression while its original value is also used in the code. Some different characters will result in the same char code when transformed. For example, “ß” and “SS” will both transform into “0x00DF” when uppercased.
Such cases are usually used to bypass/mislead some security checks by tricking the comparison check and later using the original value which is different than expected. These cases are quite elusive to grasp, especially when many implementations are possible.
AI Tool Suggestion (GitHub Copilot): A mechanism that’s particularly susceptible to this vulnerability type is the forgot password mechanism. It is common to normalize the user’s input into uppercase or lowercase (in email addresses or domain names) when performing the check in order to avoid unwelcome mismatches.
As an example, taking a look at the Copilot-generated code for the forgot password function (below) shows that it is vulnerable to this issue.
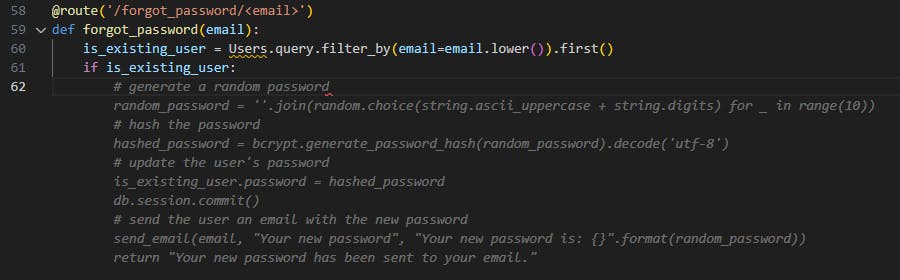
Copilot’s code first looks up the lowercased email address:

Forgot Password – Suggestion to lowercase email in query
Then, when following through with the rest of the process it suggests the following:
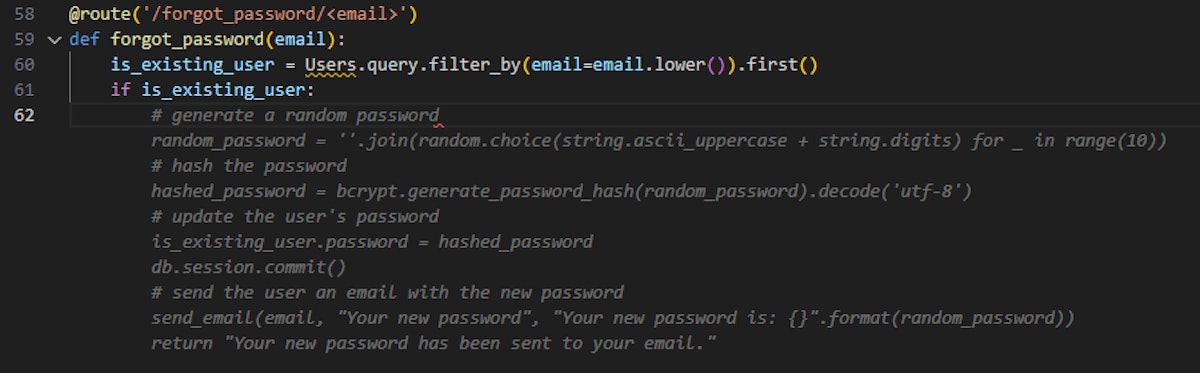
Forgot Password – Suggestion to use the original (not lowercased) email address in send_email
As we can see, the autocomplete suggestion generates a random password and sends it to the user’s email address. However, it initially uses a lowercase version of the user’s email for fetching the user account, and then continues to use the original user’s email ‘as-is’ (without a lowercase conversion) as the target of the recovery email.
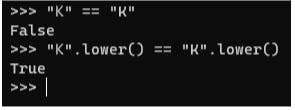
For example, lets say the attacker owns the inbox for “miKe@example.com” (the “K” is a Kelvin Sign unicode character) and uses this email for the “Forgot Password” mechanism. The emails “miKe@example.com” and “mike@example.com”, are notequivalent ‘as-is’, but after lowercase conversion they will be –
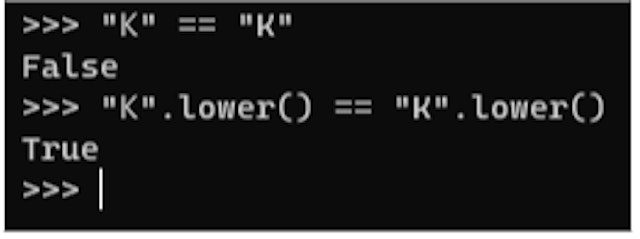
Using the email address “miKe@example.com” will fetch the account information for “mike@example.com” but the reset password will be sent to the attacker’s inbox (“miKe@example.com”), allowing takeover of the “mike@example.com” account.
Proper Implementation: The email address used for fetching the user account must exactly equal the recovery email address (i.e. send_email parameter will also use email.lower()).
In addition, as a precaution, it is recommended to use the value that was already stored in the server instead of the one supplied by the user.
- Use Case: Generating Configuration File – Bad Security Practices
Another topic that could confuse auto-complete tools is writing configuration files, especially for complicated cloud infrastructures.
The main reason is that indeed there are security best practice guidelines, but not everybody follows them, and in some cases, it is needed to go against them. Such code samples might find their way into the AI training dataset. As a result, some auto-complete outputs will violate the recommended security guidelines.
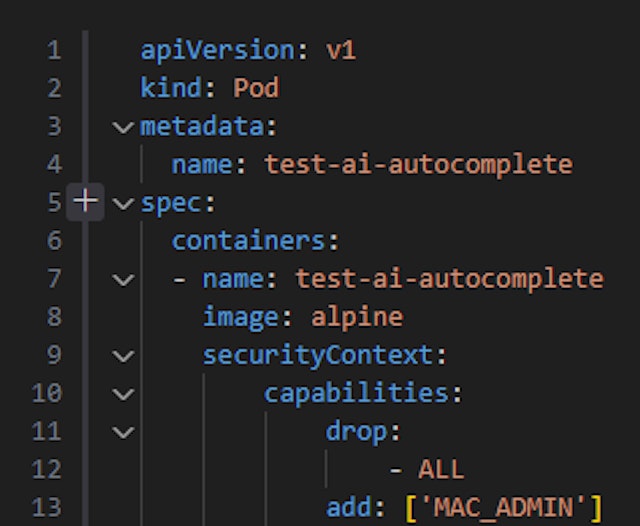
In the following example, we will create a configuration file for a Kubernetes Pod, the smallest execution unit in Kubernetes.
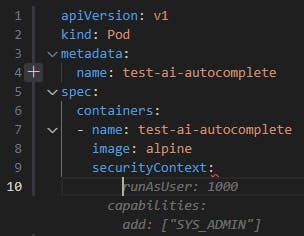
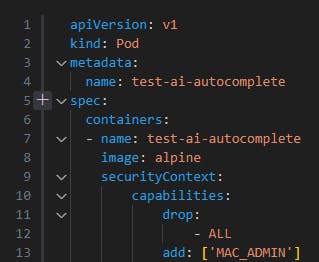
AI Tool Suggestion (Blackbox AI Code Generation): In this example, we start creating a Pod configuration file.
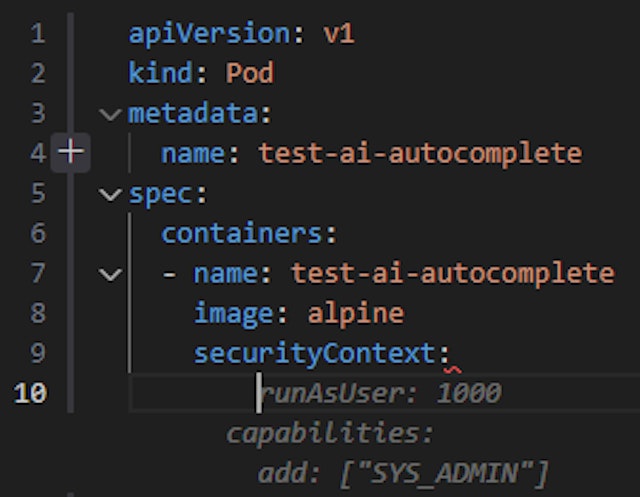
The suggestion creates the capabilities section and adds a Linux kernel capability (SYS_ADMIN) to the container which is essentially equivalent to running the pod as the root user.
Proper Implementation: Is it better to just omit the securityContext then? No – since many other capabilities will then be added by default, violating the principle of least privilege.
According to Docker security best practices, the most secure setup is to first drop all Linux kernel capabilities and only afterward add the ones required for your container.
In order to fix the issues mentioned above, the capabilities section begins by dropping all capabilities, and will then gradually add the needed ones for our container.
- Use Case: Configuration Objects – Inconsistencies Leading to Insecure DeserializationMany vulnerabilities require defining a configuration object, which decides how the application will handle the required component.
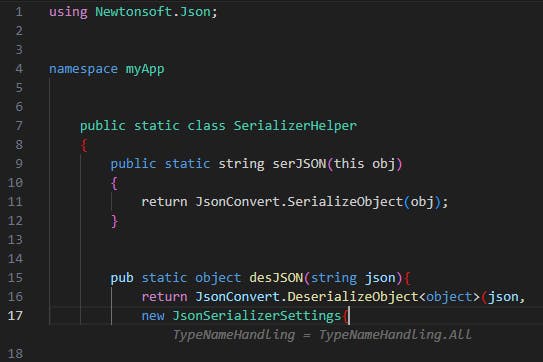
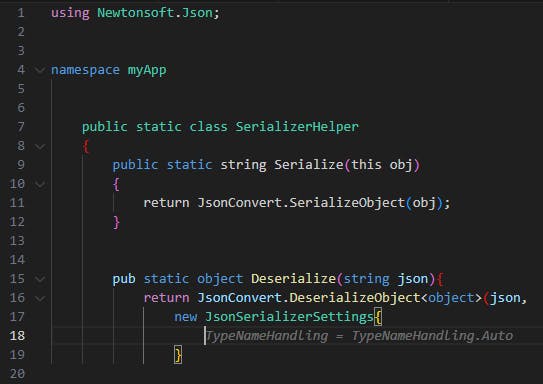
The example we chose is Newtonsoft’s JSON deserialization library in C#, which can be used securely or insecurely depending on the JsonSerializerSettings object’s configuration, and specifically, the TypeNameHandling.
While we tested the deserialization code, we noticed that the configuration object’s definition is quite random, and subtle changes can lead to generating a different configuration set.
AI Tool Suggestions (Amazon CodeWhisperer): The following examples display an inconsistent behavior that is based only on the method names used by the developer:
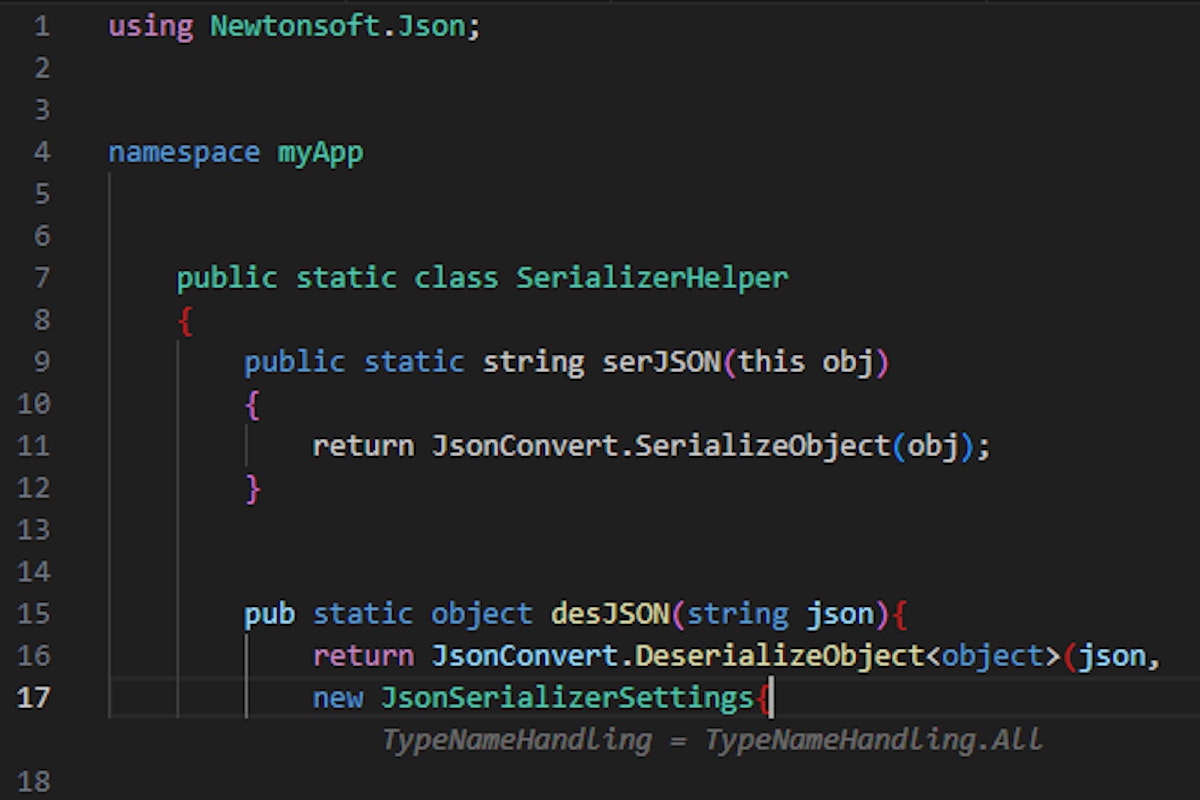
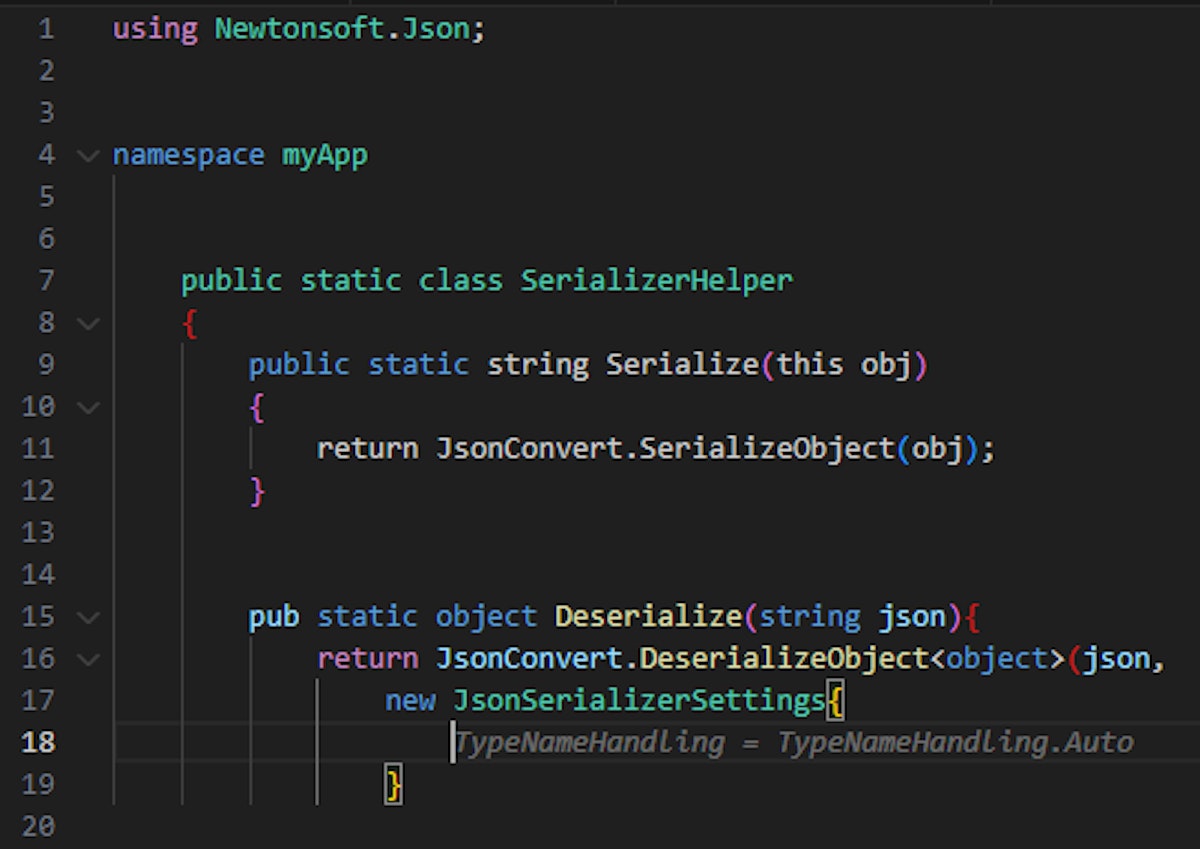
We can see two different configurations that both result in insecure JSON deserialization due to the TypeNameHandling property being “Auto” and “ALL”. These properties allow the JSON document to define the deserialized class – letting attackers deserialize arbitrary classes. This can be easily leveraged for remote code execution, for example by deserializing the class “System.Diagnostics.Process”. The only difference in the developer’s original code are the method names.
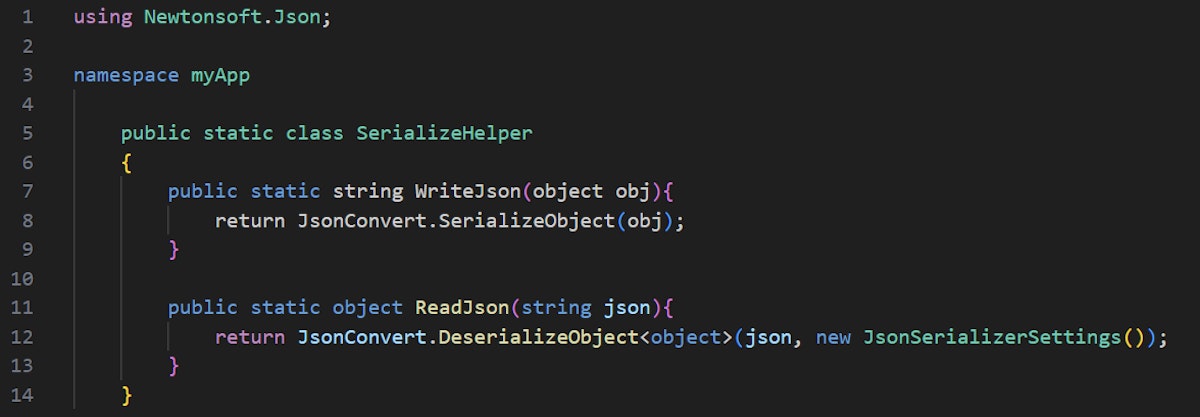
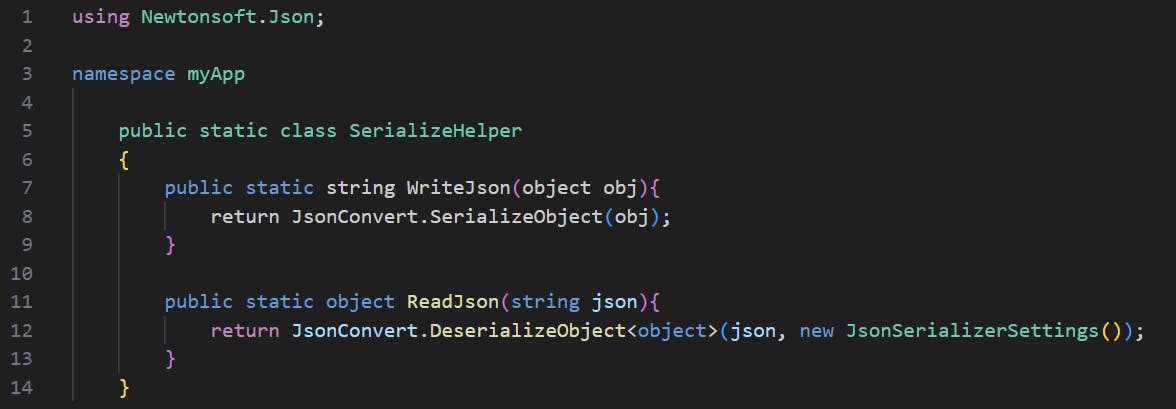
By default, a JsonSerializerSettings object is instantiated with “TypeNameHandling = TypeNameHandling.None”, which is considered to be secure. Thus, we use JsonSerializerSettings’s default constructor which will result in a safe TypeNameHandling value.
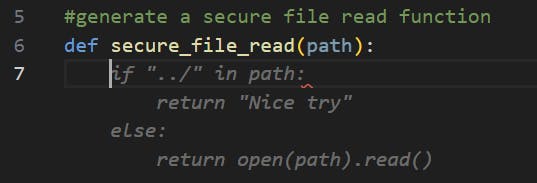
- Secure Code Request Use Case: Reading Files – Avoiding Directory TraversalSimilar to the first use case, where we examined the vulnerable code produced by Copilot for fetching files, here we attempt to request a secure version of a file reading mechanism.
AI Tool Suggestion (GitHub Copilot):
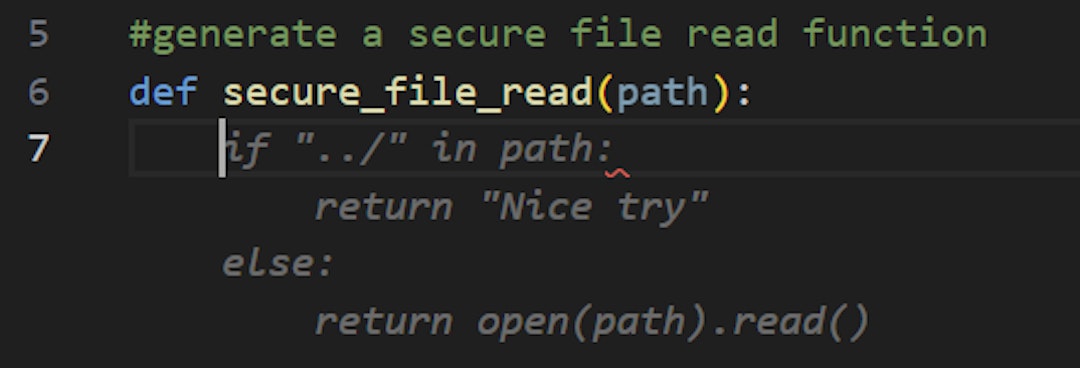
We can see that the security check is really naive, only avoiding dot-dot-slash sequences that are needed for conducting directory traversal attempts. The path parameter can be an absolute path – pointing to any desired path on the system (for example, /etc/passwd), which defeats the purpose of the security check.

Here, the secure_file_read function gets a (relative) filename parameter along with a directory (safe_dir) where the filename should reside (and which should not be escaped). It creates an absolute path by joining safe_dir and filename and proceeds to get its canonicalized form by calling realpath. It then gets the canonicalized form of the safe_dir folder. Then, the file contents are returned only if the canonicalized path starts with the canonicalized safe_dir.
- Secure Code Request – File Upload – Restricted Extensions List It is a common use case to only accept specific file types for upload based on their extension.
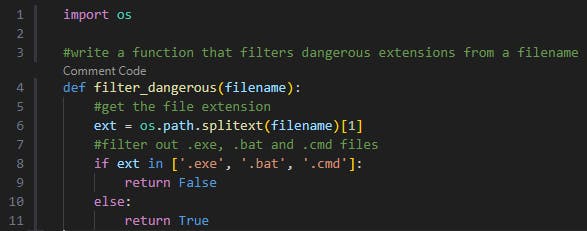
AI Tool Suggestion (Blackbox AI Code Generation): In the following example, we asked the AI auto-completer to generate a function tasked with filtering dangerous file extensions.
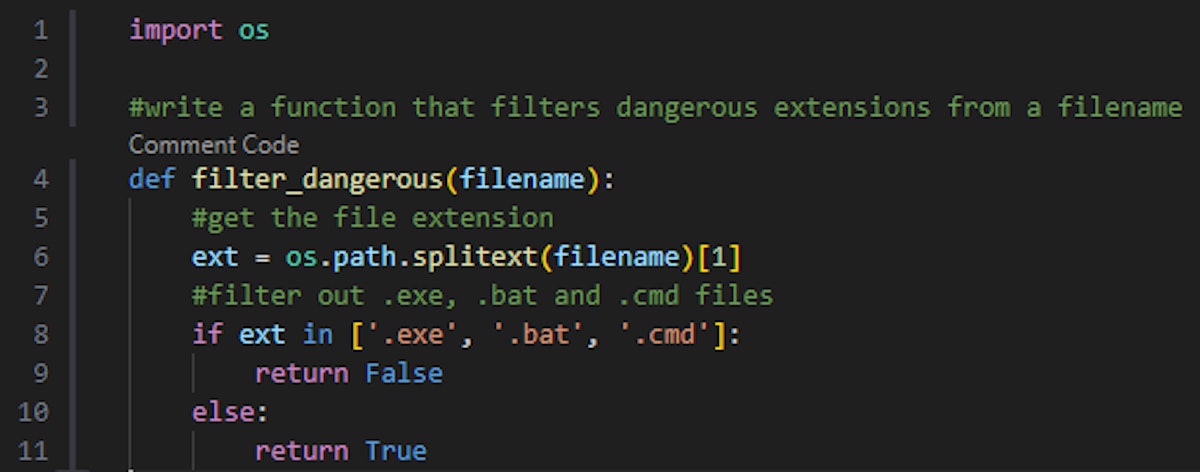
The suggested Python code takes the filename, separates the extension, and compares it against a list of dangerous extensions.
At first glance, this code snippet looks secure. However, Windows filename conventionsforbid filenames ending with a dot, and when supplying a filename ending with a dot (“.”) during file creation, the dot will be discarded. Meaning, that the generated filter could be bypassed on Windows when submitting a file with a malicious extension followed by a dot (ex. “example.exe.”).
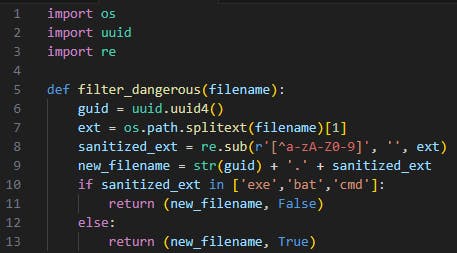
Proper Implementation: Usually the better approach is to use a whitelist, which checks the file extension only against allowed extensions. However, since the tools took a blacklist approach (which is needed in some cases) we will outline a safer blacklist implementation:
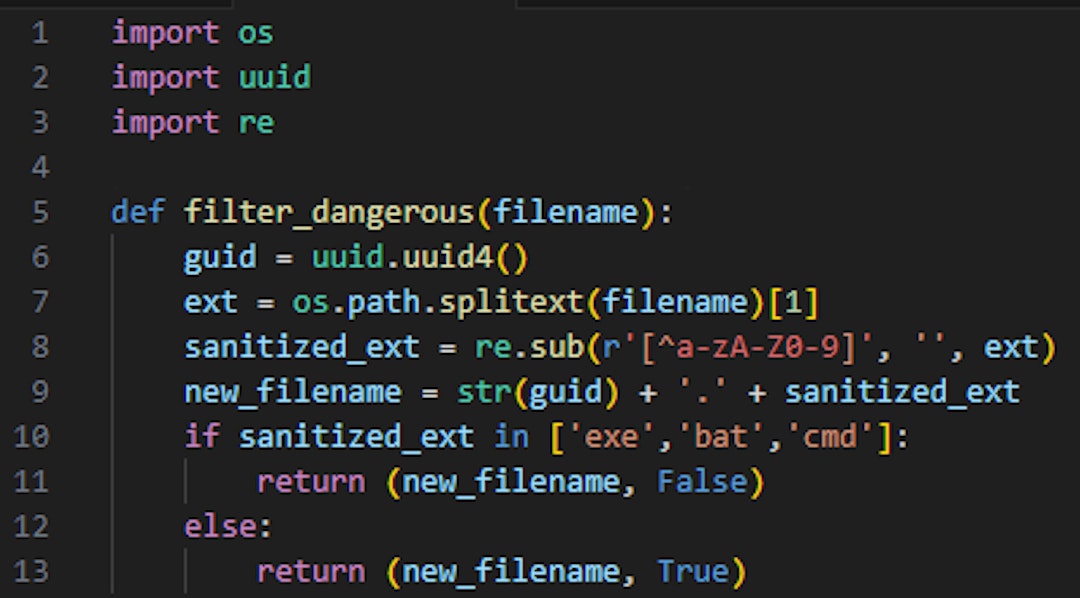
In the following snippet, we strip away as much control the user had on the input by stripping the extension from all non-alphanumeric characters and concatenating it to a newly generated filename.
Bottom line – use with caution Automatic co-programmers are great for suggesting ideas, auto-completing code, and speeding up the software development process. We expect these tools to keep evolving as time goes on, but for now as demonstrated with the use cases in this post, auto-complete AI solutions have many challenges to overcome until we can ease our minds and trust their output without double-checking for bugs.
A possible way to reduce the likelihood of introducing vulnerabilities is deliberately requesting the AI code generation tool to generate secure code. Although this may be useful in some use cases, it is not foolproof – the “seemingly secure” output should still be reviewed manually by someone proficient in software security.
JFrog Security Research Team Recommendations To help secure your software, we recommend both manually reviewing code produced by AI generative tools, as well as incorporating security solutions such as Static Application Security Testing (SAST) which can trustfully discover vulnerabilities as you go. As seen in the example above, SAST tools can alert and catch the unicode case mapping collision described in use case #3. This proactive approach is essential to ensuring the security of your software.
Stay up-to-date with JFrog Security Research The security research team’s findings and research play an important role in improving the JFrog Platform’s application software security capabilities.
Follow the latest discoveries and technical updates from the JFrog Security Research team on our research website, and on X @JFrogSecurity.
This article was originally published by Natan Nehorai on Hackernoon.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}